Tips for SOCLess Oncall
Handling alerts when there's no alert handlers
Tell me if you’ve heard this one before.
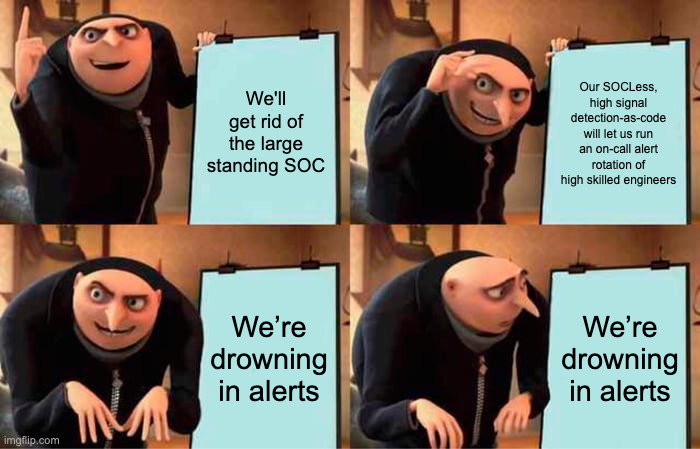
The last thing we want is a bunch of lame alerts creating busy work for a large standing SOC.
Instead, we’ll take an adaptive, agile, and highly automated approach to threat management (Autonomic Security Operations / SOCLess)
We’ll use detection-as-code, and an on-call alert rotation instead of a triage bench
We’re drowning in alerts
What is a SOCLess Oncall / Autonomic Security Operations?
🟰 Because I want to, I’m going to treat these two terms interchangeably, and lean on SOCLess as the pithier one.
SOCLess was coined by Alex Maestretti, based on Netflix’s program. The core tenants were:
- Avoid a large standing SOC, by
- Focusing on mature rules with defined response plans, where
- Alerts triage is decentralized to system experts, and
- You own the alerts you write
Autonomic Security Operations is mostly an Anton Chuvakin-ism. It builds on years of his writing (at Gartner, and later at Google). It includes:
- 10X analyst productivity and effectiveness through upskilling and automation
- 10X process through “automation, consistent and predictable processes running at machine speed”
- 10X technology through comprehensive visibility, interoperability, performance, and improved quality of detection signals
These two approaches try to move the time (and staffing) a SOC traditionally spends on repetitive alert triage into engineers working on wiring controls into a detection and response platform, and overall doing work that compounds (versus toil).
SOCLess Oncall Friction
🤐 Don’t mind the man behind the curtain … my biases (naivete? youth?): I’ve actually never worked at a company with a traditional SOC!
Instead, the security teams I’ve worked with all navigate this “SOCLess” model, amidst generally cloud-native environments at companies building SaaS.
I’ve noticed a pattern. SOCLess detection programs still have the same innate entropy towards lowered signal. In a traditional SOC, this might result in ineffective staffing, analyst burn out, or reduced triage efficacy.
In a SOCLess program, the risks can also put tension on the strategic decision to run SOCLess and can stress the cultural identity of teams that choose this approach.
Let’s circle back:
The last thing we want is a bunch of lame alerts creating busy work for a large standing SOC.
But we have a bunch of clever alerts, based on the latest and greatest threat research scooped from the pages of Detection Engineering Weekly, that will be our only signal someone has $DONE_THE_BAD_THING!
Instead, we’ll take an adaptive, agile, and highly automated approach to threat management (Autonomic SOC / SOCLess)
But our alerts are generally constructed in isolation, by a single engineer, as a side task during their real project
We use detection-as-code, and an on-call alert rotation
But that alert rotation really is a triage desk, and also a runner (in the Stripe mold), handling not just alerts but also inbound requests from humans. Also, they should have time to work on other engineering tasks during their oncall week, not just handle alerts
But our skilled engineers are skilled at application security, or 1337 hAckS, or cryptography, not at operations or detection engineering
I think a root cause of this issue is that SOCLess is often adopted as a repudiation of the traditional SOC, more than as a holistic strategy. It starts with the conviction that great teams are not solving detection problems with analysts.
Engineering-oriented security teams, especially at cloud-native startups, want to take an engineering-led approach to detection and response. SOCLess? Well, if it worked for Netflix and Google…
This reflexive move skips the scaffolding and primitives that make SOCLess viable - causing the drift towards noise and tension in operations and oncall.
But it doesn’t have to be this way! I think there are a few core primitives that can buy you a lot of scale in your SOCLess program.
Alert Taxonomy
The cardinal sin of immature SOCLess might be a failure to set Alert Taxonomy.

Alert Severity is notoriously squirrely - check out Absolute measurement corrupts severity, absolutely. Despite the challenges, many teams set up Info/Low/Medium/High and go on their way. What they miss is that a SOCLess program actually should generate a few distinct classes of alerts.
🧠 This is heavily inspired by Datadog’s Monitoring 101: Alerting on what matters
- Records: alerts that are not timely, but might be useful for future reference or investigation. This may also includes alerts that are part of a Correlated Alert but are not actionable on their own.
- Notifications: alerts that require further analysis or intervention, but where response can be delayed. The SLA might be on the order of hours, not minutes. Charity Majors calls these “second lane alerts,” which I like.
- Pages: alerts that require immediate analysis or intervention from the security on-call.
There is actually one more level of granularity that we’ll circle back to - the User Notification.
Alert Handling
Setting a taxonomy is mostly powerful in how it implies consistent tactics for alert handling. This composes the where, what, and when of alert response.
For example: Pages go to our Ticketing System and Pagerduty where they are ACK’d within 5 minutes. All tickets are reviewed weekly in our retro.
The use of a taxonomy also allows for more flexibility in coordination with the severity. You might want to retro and resolve High Risk Notifications, but auto-close Low Risk ones.
Automation Maturity
This diversity in Alert Handling implies a third pre-requisite to run SOCLess - Automation Maturity. Small teams often lack the dedicated staffing against detection engineering that might happen at Netflix-scale. As a result, many of the automation platforms end up built in parallel to alert development, or a SaaS SOAR might be adopted with its own set of challenges.
Twilio’s SOCLess is an example of the standard architecture I’ve seen teams build, which throws together Lambdas with other cloud infrastructure. These platforms are easy to start but can be hard to scale. The mix of a flexible workflow platform with data engineering challenges results in a problem that can be hard to address along the edges of your days.
Tines’ SOC Automation Capability Matrix offers a good survey of how broad the capabilities can be in a fully automated setup.
I’d highlight User Interaction as the oft-missing stair in small SOCLess programs. The minimally loveable shape is:
- A single interface, often Slack
- Acknowledgement (this was me), or disavowel (uhhh, what is this?) - with timed escalation
- Strong MFA prompting
This capabilities unlocks the fourth alert type, the User Notification: alerts that require more information from a human to become record, security notification, or page.
This contributes to a crucial element of the SOCLess model — the ability to distribute alerts to system owners (aka alert decentralization).
your SOC team is basically an air traffic controller - they assess what’s going on and they direct the issue to the where it needs to go - but they aren’t actually flying the plane.
If this is the case, why can’t we simply automate this air traffic controller process? For example, if a laptop’s endpoint protection fires an alert, why not direct it right to IT?
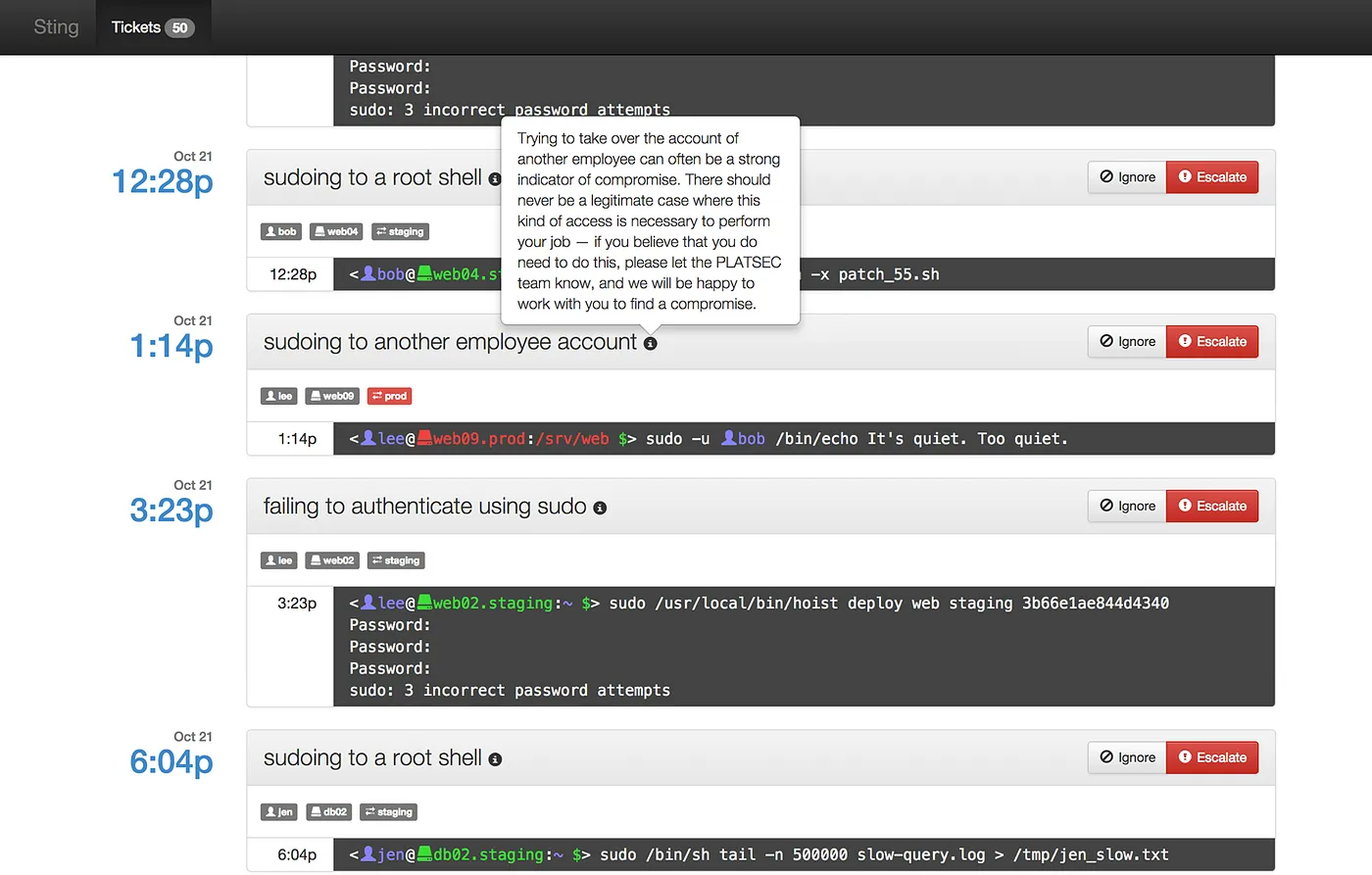
Take inspiration for your User Notifications from Square:
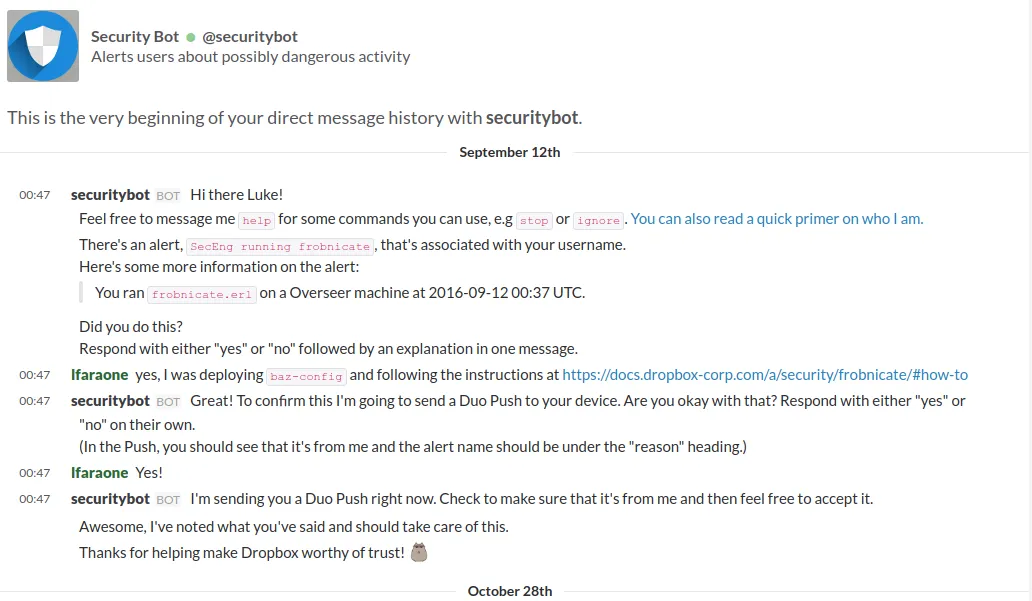
and Slack:

💭 Fun fact: Crowdalert co-founder & CTO John Sonnenschein was on the team at Slack that worked on
securitybot! They’ve been tackling this problem for almost a decade, and Crowdalert is the culmination of lots of lessons learned.
Karthik Rangarajan has some great notes on how OpenAI takes this a step further by integrating LLMs!
Playbook: Maturing your SOCless Oncall
So, we have a diagnosis and cure, but what’s the course of treatment?
☎️ Looking for a quick path to increased signal and reduced alert fatigue? Reach out for a demo of Crowdalert’s platform for Alert Verification, Prioritization, Dispatch, and Identity Visibility.
Feel free to skip steps based on your current maturity!
- Classify existing alerts: revise severity (but don’t overthink it!) and set metadata on alert type (Record, User Notification, Security Notification, Page)
- Create the requisite hierarchies in adjacent systems (Slack channels, ticket types, etc.) for alert routing
- Implement minimally lovable automation:
- Quality Deduplication: with grouping and snoozing
- User Notification
- Move from atomic alerts to correlated ones, where possible
- Standardize maturity requirements, based on alert type: for example, all Pages have a low-to-no False Positive tolerance, and all Notifications and Pages must trigger automation before alerting. All Notifications and Pages must have a concrete runbook.
- Set up a process to monitor alert health and program metrics on an ongoing basis
- Set up a process to monitor program metrics on an ongoing basis
References
- Netflix SIRT - FIRST Podcast 2018
- FOX is SOCLess
- Going SOCLess at Flexport
- Autonomic Security Operations - 10X Transformation of the Security Operations Center
- RIP SOC. Hello D-IR
- Absolute measurement corrupts severity, absolutely
This post was written by Rami McCarthy for Crowdalert.
- By
- Rami McCarthy
Last Updated 2024.07.23